3A_chap8-multi-processor_management
 times read
times read
Contents
1. 简介
Intel 提供了管理和提高连接到相同系统总线的多处理器性能的机制 , 包括 :
- 对系统内存执行原子操作所需的总线锁和 cache 一致性管理
- 串行化的指令
- 位于处理器芯片的 APIC
- L2 cache
- L3 cache
- Intel 超线程技术 , 单个处理器核心并发执行两个或多个线程
Intel 提供的多处理器机制有以下特点 :
- 维护系统内存的一致 ( coherency )
- 维护 cache 一致性 ( consistency )
- 允许按照预期的次序写入内存
- 在一组处理器间分发中断处理
- 开发当前操作系统和应用的多线程和多进程提升系统性能
2. Locked Atomic Operations
32 位 IA-32 处理器支持系统内存地址的带锁原子操作 , 通常用于管理共享的数据结构 ( 信号量 , 段描述符 , 系统段 , 页表 ) . 处理器采用三个独立的机制实现带锁的原子操作 :
- 保证的原子操作
- 总线锁 , 使用 LOCK# 信号和 LOCK 指令前缀
- 确保可以再缓存的数据结构上执行原子操作的 cache 一致性协议 ( cache 锁 )
软件需要保证访问锁的公平性 , 防止锁饿死 .
2.1. 保证的原子操作
下列基本内存操作会被原子的执行 :
- 读写一个字节
- 读写一个对齐到 16-bit 的字
- 读写一个对齐到 32-bit 的双字
- 读写一个对齐到 64-bit 的四字
- 32 位数据总线对于 uncached 内存地址的 16-bit 访问
- 对于一个 cache line 内的已缓存内存的未对齐的 16-bit , 32-bit , 64-bit 访问
2.2. 总线锁
LOCK# 信号在某些临界内存操作时自动使能 , 锁住系统总线或者等价的连接 . 这个输出信号使能时 , 其他处理器或者总线 agent 控制总线的请求会被阻塞 . 软件可以添加 LOCK 前缀到一条指令来指明其他需要遵守 LOCK 语义的场景 .
在 P6 以后的处理器中 , 如果访问的内存区域缓存在处理器内部 , 通常不会使能 LOCK# 信号 ; 锁只适用于处理器的 cache .
处理器自动遵守 LOCK 语义的操作如下 :
- 执行引用内存的
XCHG指令 - 设置 TSS 描述符的忙标志 , 防止两个处理器切换到相同的任务
- 更新段描述符
- 更新页目录和页表中的项
- 响应中断
下列命令可以添加 LOCK 前缀 , 显式强制进行 LOCK 语义 . 其他指令使用 LOCK 前缀 , 或者没有写入内存 ( 指令的目的操作数是一个寄存器 ) 的操作都会产生 #UD :
- 位测试和修改指令 (
BTS,BTR,BTC) - 交换指令 (
XADD,CMPXCHG,CMPXCHG8B) - 自动假设
XCHG指令带有 LOCK 前缀 - 下列单操作数的数学和逻辑指令 :
INC,DEC,NOT,NEG - 下列双操作数的数学和逻辑指令 :
ADD,ADC,SUB,SBB,AND,OR,XOR
有锁的操作对于所有的内存操作和外部可见的事件都是原子的 , 只有取指和页表访问可以通过带锁的指令 .
如果 LOCK 操作中访问的内存区域作为写回内存被缓存到执行锁操作的处理器中 , 而且完全包含在一个 cache 行中 , 处理器可能不会使能总线上的 LOCK# 信号 .
相反 , 处理器会修改内部的内存 , 使用 cache 一致性机制保证操作被原子的执行 .
3. 内存次序
memory ordering 指处理器通过系统总线向系统内存发出读写指令的次序 , 不同的 Intel 架构支持不同的内存次序模型 .
Intel 386 处理器使用 program ordering ( 也叫作 strong ordering ) , 所有情况下系统总线发出读写操作的次序和指令流中的次序相同 .
IA-32 架构引入了 processor ordering , 允许提升性能的操作 , 例如读操作在带有缓冲的写操作前执行 , 从而在维持内存一致性的前提下提升指令的执行速度 .
3.1. Pentium 和 486 处理器
Pentium 和 486 处理器使用 processor ordering 内存模型 , 但是大多数情况下的操作和 strong ordering 模型一样 . 读和写总是按照编程模型出现在系统总线 , 除了下列展示出 processor ordering 的情形 :
所有的带缓冲的写操作都 cache 命中时 , 系统总线上的读 miss 可以超过带缓冲的写 , 因为后者不会指向和读 miss 操作访问的相同地址 .
IO 操作中 , 读和写总是按照编程次序出现 .
3.2. P6 和更新的处理器
更新的处理器也采用 processor ordering 内存模型 , 可以被定义为 write ordered with store-buffer forwarding .
内存区域定义为 write-back cacheable 的单处理器系统中 , 内存模型遵守一系列的原则 .
多处理器系统的单个处理器需要遵守单处理器的内存模型原则 , 还需要额外的规则 .
- load 和 store 都无法和同类型的操作重新排序
- store 和更早的 load 无法重新排序
- load 和更早的不同内存地址的 store 可以重新排序
- 两个处理器都觉得自己的 store 发生在另一个处理器的 store 之前 , 允许处理器内的前递
- 两个处理器的 store 次序 , 在其他的处理器看来是一致的
- 带锁的指令只有一个执行次序
- load 和 store 不能和带锁的指令重新排序
字符串操作指令的内存次序遵守以下规则 :
- 一个字符串操作内的 store 可以重新排序
- 字符串操作间的 store 无法重新排序
- 字符串操作无法和后续的 store 重新排序
3.3. 增强或减弱内存次序
下列机制可以用于增强或者减弱内存次序 :
- IO 指令 , 锁指令 , LOCK 前缀和序列化指令可以用于增强内存次序
SFENCE,LFENCE,MFENCE可以序列化特定类型的内存操作- 内存类型范围寄存器 ( MTRR ) 可以用于加强或减弱特定物理内存区域的内存次序
- 页属性表 ( PAT ) 可以用于加强特定页或一组页的内存次序
FENCE 指令提供了保证产生弱次序结果的例程和使用这个结果的例程间 load 和 store 内存次序的高效方式 , 这些指令的功能如下 :
SFENCE
序列化所有发生在SFENCE指令之前的 store 操作 , 不影响 load 操作 .LFENCE
序列化所有发生在LFENCE指令之前的 load 操作 , 不影响 store 操作 .MFENCE
序列化所有发生在MFENCE指令之前的 store 和 load 操作 .
FENCE 指令比 CPUID 指令控制内存次序的效率更高 .
4. Multiple-Processor ( MP ) Initialization
多处理器初始化协议有专门的 specification , 定义了两种处理器 : bootstrap processor ( BSP ) 和 application processor ( AP ) .
系统上电或重启后 , 系统硬件动态选择系统总线上的一个处理器作为 BSP , 其余的处理器作为 AP .
BSP 的 IA32_APIC_BASE MSR 的 BSP 标志会置位 , 指明自己是一个 BSP , 其他处理器的这个标志都会清除 .
BSP 执行 BIOS 的 bootstrap 代码 , 配置 APIC 环境 , 建立系统范围的数据结构 , 开始初始化 AP . BSP 和 AP 初始化完成后 , BSP 执行 OS 的初始化代码 .
系统上电或重启后 , AP 完成最小化的自配置 , 然后等待 BSP 处理器的启动信号 ( 通过 SIPI 消息 ) ; 收到 SIPI 消息后 , AP 执行 BIOS AP 配置代码 , 完成后处于 halt 状态 .
支持 Intel 超线程技术的处理器 , MP 初始化协议将系统总线上或 coherent link domain 的每个逻辑处理器作为一个单独的处理器 ( 有唯一的 APIC ID ) .
MP 协议只有在上电或者 RESET 后才会执行 , 如果 MP 协议已经完成 , 选择了一个 BSP , 后续的 INIT 不会导致 MP 协议被重复 .
MP 初始化期间 , 系统中所有可以传递中断的设备必须被阻止发送中断给处理器 .
4.1. MP 初始化协议算法
MP 系统执行初始化协议期间 , 会执行以下操作 :
- 给每个逻辑处理器分配一个唯一的 APIC ID , 基于系统拓扑 . 支持 CPUID 叶子 0BH 的处理器 ID 为 32-bit , 否则是 8-bit .
- 基于 APIC ID 给每个逻辑处理器分配一个唯一的仲裁优先级 .
- 每个逻辑处理器同时执行 BIST .
- 较新的处理器中 , 仲裁优先级最高的逻辑处理器成为 BSP .
- 作为 bootstrap 代码的一部分 , BSP 创建 ACPI 表和 / 或 MP 表 , 添加初始 APIC ID 到表中 .
- bootstrap 结束处 , BSP 设置一个处理器的计数器为 1 , 广播一个 SIPI 消息到系统中所有 AP . SIPI 消息包含 BIOS AP 初始化代码的向量 .
- AP 初始化的第一个操作是针对一个 BIOS 初始化信号量创建一个竞争条件 , 获得信号量的第一个 AP 执行初始化代码 . 作为 AP 初始化过程的一部分 , AP 添加自己的 APIC ID 到 ACPI 和 / 或 MP 表 , 增加处理器计数 1 , 初始化完成后 , AP 执行
CLI指令 , 停止自己 . - 每个 API 都访问过信号量 , 执行 AP 初始化代码后 , BSP 统计连接到系统总线的处理器的数量 , 完成 BIOS 的 bootstrap 代码 , 开始执行 OS 的 bootstrap 和启动代码 .
- BSP 执行 OS 的 bootstrap 和启动代码时 , AP 保持在停止状态 , 只会响应 INIT , NMI 和 SMI ; 也会响应 snoop 和 STPCLK# 的使能 .
4.1.1. 典型的 BSP 初始化序列
IA-32 架构 BSP 从地址 0xFFFFFFF0H 开始执行 BIOS 的 bootstrap 代码 , 通常执行以下操作 :
- 初始化内存 .
- 加载 microcode 的更新到处理器 .
- 初始化 MTRR .
- 开启 cache .
- EAX = 0H 时执行 CPUID 指令 , 然后读取 EBX , ECX 和 EDX 的值, 判断 BSP是否是 “GenuineIntel” .
- EAX = 1H 时执行 CPUID 指令 , 保存 EAX , ECX 和 EDX 寄存器的值到 RAM 中的系统配置空间 , 供以后使用 .
- 加载 AP 要执行的启动代码到低 1MB 内存的一个 4KB 页 .
- 切换到保护模式 , 保证 APIC 地址空间映射到一个 strong uncacheable 内存类型 .
- 从本地 APIC ID 寄存器确定 BSP 的 APIC ID , 保存到 ACPI 和 / 或 MP 表 .
- 将 AP 的启动代码所在的 4KB 页的基地址转化为 8-bit 向量 , 后者定义了 4KB 页在实地址模式下的地址 .
- 设置 APIC spurious vector register 的 bit 8 , 开启本地 APIC .
- 通过给 APIC 错误处理函数建立一个 8-bit 向量设置 LVT 错误处理项 .
- 初始化 Lock 信号量变量 VACANT 为 00H , AP 使用这个信号量确定执行 BIOS AP 初始化代码的次序 .
- BSP 通过 COUNT 变量探测系统中的 AP .
- 广播一个 INIT-SIPI-SIPI IPI 序列到 AP , 唤醒并初始化 AP .
- 读取 COUNT 变量 , 建立一个处理器计数 .
- 如果有必要 , 重新配置 APIC , 继续剩余的系统诊断 .
AP 需要等待 BIOS 初始化 Lock 信号量 , 获取后继续初始化 . AP 不需要执行第 7 步 , 并且在增加 COUNT 变量后释放信号量 , 进入停止状态 , 等待 INIT IPI .
支持 Intel 超线程技术的的处理器系统的初始化过程和传统的 MP 系统的初始化流程相同 .
完成 OS 启动过程后 , BSP 执行 OS 代码 , 其他的逻辑处理器处于 halt 状态 . 要在停止的处理器执行代码 , OS 发送一个指向被挂起的逻辑处理器的 IPI ( 处理期间中断 ) . 作为回应 , 处理器唤醒 , 开始执行 IPI 中包含的向量指明的代码 .
5. Intel 超线程技术
支持超线程技术的逻辑处理 , 一个物理处理器内的逻辑处理器共享 MTRR , 每个逻辑处理器都有自己的通用寄存器 , EFLAGS 等大多数寄存器 .
一个处理器内的逻辑处理器共享下列信号 : STPCLK# 和 LINT0 , LINT1 .
6. 编程支持多线程的处理器需要考虑的事
支持多线程的处理器硬件内 , 一些资源由处理器核心共有 , 其他的资源每个逻辑处理器都有 .
从软件的角度看 , 处理器操作的控制转换以逻辑处理器的粒度进行管理 , 为了管理多线程环境下共享资源的拓扑 , 理解和管理由超过一个逻辑处理器共享的资源对于软件可能十分有用 .
6.1. 共享资源的分级映射
每个逻辑处理器的 APIC ID 由多个域组成 , 每个域对应硬件资源的拓扑学映射的分层等级 .
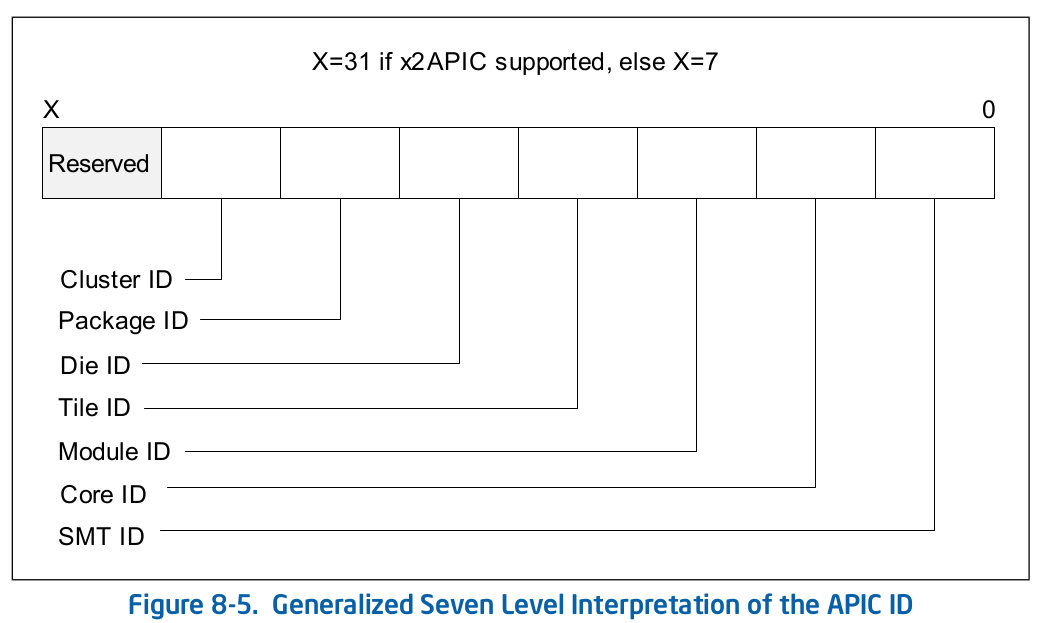
如果处理器支持 CPUID 叶子 0BH 和 1FH , 32-bit 的 APIC ID 可以代表 cluster 加上一些拓扑分级 .
有效的 APIC ID 不需要在 package 或 core 边界保持连续 .
7. 空闲和阻塞条件的管理
MP 系统中的一个逻辑处理器空闲或者被阻塞时 , 可以通过 HLT , PAUSE , MONITOR / MWAIT 指令对执行引擎资源进行额外的管理 .
7.1. HLT 指令
一个逻辑处理器被停止后 , 物理 package 内的其他逻辑处理器仍然能够访问共享的资源 , 更高效的执行指令 .
被停止的指令恢复执行后 , 共享的资源重新在所有的活跃处理器间共享 .
7.2. PAUSE 指令
PAUSE 指令可以提高支持超线程技术的处理器在执行 “spin-wait loop” , 以及其他的一个线程在紧密的轮训中访问一个共享的锁或信号量时的性能 .
执行 spin-wait loop 时 , 处理器在退出循环时性能会严重下降 , 因为处理器会探测到一个可能的违反内存次序 , flush 核内处理器的流水线 .
PAUSE 指令提示处理器代码序列是一个 spin-wait loop , 处理器通过这个提示避免违反内存次序 , 阻止流水线 flush . 此外 , PAUSE 指令 de-pipeline spin-wait loop , 防止其消耗额外的执行资源和不必要的电量 .
7.3. 通过 MONITOR / MWAIT 指令
Streaming SIMD Extensions 3 引入了两个指令 ( MONITOR 和 MWAIT ) 帮助多线程软件提升线程同步 .
最初的实现中 , 两条指令只有 ring 0 的软件可用 , 特权级高于 0 时有条件的可用 .
OS 通常使用空闲的循环实现线程同步 , 典型的情况中 , 可能有一些 “busy loops” , 使用一些内存区域 . 受影响的处理器在一个循环中等待 , 轮训内存区域 , 确定是否有可用的任务需要处理 . 任务的发布通常是一个对内存的写 , 初始化一个任务请求并进行调度的时机和几个总线 cycle 的次序相同 .
从资源共享的角度 , 在 OS 空闲循环使用 HLT 指令是可取的 , 但是会有不良影响 . 在空闲处理器执行 HLT 指令会将处理器至于不可执行的状态 , 需要另外一个处理器发送 IPI 唤醒 , 导致延迟 .
在共享内存的配置中 , 从忙循环退出通常由于特定内存区域的状态改变 , 这种改变倾向于由另一个处理器对于内存的写触发 .
MONITOR / MWAIT 补足了 HLT 和 PAUSE 的使用 , 允许在共享物理资源的逻辑处理器间高效的划分和归并共享资源 .
MONITOR 建立一个有效的地址范围 , 用于监测写入内存的活动 ; MWAIT 将处理器置于最优状态 , 直到被监测的内存发生写入 .
两条指令都依赖于处理器的监测硬件的状态 , 监测硬件可以通过 MONITOR 装备 , 也可以通过一些事件触发 .
执行 MWAIT 时 , 监测硬件处于被触发的状态 : MWAIT 和 NOP 行为类似 , 执行流的下一条指令继续执行 . 监测硬件的状态不可见 , 只能通过 MWAIT 的行为体现 .
除了写入监测的地址范围 , 多个事件可以唤醒执行过的 MWAIT , 包括可能导致自愿或者非自愿的上下文切换的事件 :
- 外部中断 , 包括 NMI , SMI , INIT , BINIT , MCERR , A20M#
- fault , abort ( 包括机器检查 )
- TLB 无效 , 包括写入 CR0 , CR3 , CR4 和一些 MSR ;
LMSW的执行 - 快速的系统调用和远调用导致的自愿 transition
电源管理相关的事件和 fualt 不会导致监控事件挂起标志被清除 .
软件不应该允许指令流中的 MONITOR / MWAIT 之间的自愿上下文切换 , MWAIT 的执行不会重新装备监测硬件 , 这意味着 MONITOR / MWAIT 需要在一个循环内执行 .
此外 , 从 MWAIT 状态退出可能由于写入触发地址外的条件导致 , 软件应该显式检查触发数据位置确定是否发生了写 . 软件还应该在执行监测指令后检查触发地址的值 ( MWAIT 指令前 ) , 识别出 MONITOR 执行期间发生的针对触发地址的写 .
提供给 MONITOR 指令的地址范围必须是写回的缓存类型 , 只有写回内存类型的 store 才会触发监测硬件 ; 否则地址监测硬件可能无法正确建立 , 监测硬件也无法装备 .
7.4. MONITOR / MWAIT 地址范围的确定
软件需要知道 MONITOR / MWAIT 指令监测的区域大小以使用两个指令 , 需要确定最小的和最大的监测行大小 :
- 为了避免错过的唤醒 : 确保用于监测写的数据结构适用于最小的监测行大小 ; 否则 , 处理器可能在退出
WMAIT的写之后没有被唤醒 . - 为了避免假的唤醒 : 使用最大的监测行大小 , 填补用于监测写的数据结构 , 软件必须保证
MWAIT的触发区域不包含数据结构外的数据 .
7.5. 操作系统所需的支持
下列方法可以用于更好的利用共享执行资源的逻辑处理器 :
- 在 spin-wait loops 中使用
PAUSE指令 - 在 C0 空闲循环中使用
MONITOR/MWAIT - 停止空闲的逻辑处理器
- 在 C1 空闲循环中使用
MONITOR/MWAIT - 在共享执行资源的逻辑处理器间调度线程
- 消除给予执行的时序循环 ( 不要基于处理器的执行速度测量时间 )
- 将锁和信号量保存到对齐的 128 字节内存中
Author Globs Guo
LastMod 2020-09-25